
Appearance
注意力机制(attention mechanisms)
查询、键和值
在注意力机制的背景下,自主性提示被称为查询(query)。
给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。这些感官输入被称为值(value)。
每个值都与一个键(key)配对,这可以想象为感官输入的非自主提示。
注意力机制
“是否包含自主性提示”将注意力机制与全连接层或汇聚层区别开来。
| 特性 | 注意力机制 | 全连接层 | 汇聚层 |
|---|---|---|---|
| 参数化 | 是(动态权重) | 是(静态权重) | 否(固定规则) |
| 自主性提示 | ✅ 动态适应输入 | ❌ 静态处理 | ❌ 静态处理 |
| 输入依赖性 | 高度依赖 | 不依赖 | 不依赖 |
| 典型应用 | Transformer, NLP | 传统分类模型 | CNN 的空间降维 |
通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向(智能选择)。
注意力汇聚(attention pooling)
查询(自主提示)和键(非自主提示)之间交互形成注意力汇聚,注意力汇聚有选择地聚合值(感官输入)以生成最终输出。
平均汇聚忽略了键的作用,不够聪明。因此根据查询和键相对位置加权,是一个更好的想法。
其中
受此启发,可以写一个更加通用的注意力汇聚attention pooling公式:
其中
下面考虑一个高斯核Gaussian kernel,其定义为:
代入高斯核,并推导公式:
如上可知,一个键
TIP
越接近、越相似、权重越高。“查询-键”对越近,注意力汇聚注意力权重就越高。
注意力评分函数
上面使用高斯核对查询和键之间关系建模,高斯核指数部分视为注意力评分函数,简称评分函数(scoring function)。
| 评分函数 | 计算方式 | 适用场景 |
|---|---|---|
| 高斯核 | 局部相关性、空间或时间连续性 | |
| 点积 | 查询和键维度相同,高维向量,效率优先 | |
| 加性注意力 | 查询和键维度不同,复杂关系,可学习交互 | |
| 余弦相似度 | 方向相似性(忽略向量长度) |
缩放点积注意力(Scaled Dot-Product Attention)公式:
Transformer 默认缩放点积注意力,主要基于计算效率、理论合理性和实践效果综合考量。
key 相同时权重均匀分布
当所有的键(Key)相同时,计算出的注意力权重会均匀分布。所以键是决定性因素。
详细解释
- 注意力权重的计算过程:
- 假设我们有一组查询
和一组键 。对于每一个查询 ,我们计算它与所有键 的相似度(通常通过点积或其他相似度度量)。 - 然后,对这些相似度进行 softmax 操作,得到注意力权重
:
- 这些权重表示在生成输出时,每个值
的重要性。
- 所有键相同的情况:
- 如果所有的键
都相同,即 ,那么对于任意查询 :
- 因此,所有的相似度
都相同,假设这个相同的值为 。 - 计算 softmax 时:
- 因此,所有的注意力权重
都等于 ,即均匀分布。
- 直观理解:
- 键的作用是为查询提供“应该关注哪些部分”的信息。如果所有的键都相同,那么查询无法区分哪些部分更重要,因此只能均匀地关注所有的部分。
- 类似于在人群中,如果所有人的声音完全相同,你无法区分谁在说什么,只能平均听取所有人的意见。
实例演示
假设:
- 查询
。 - 键
。 - 计算点积:
- 计算 softmax:
- 因此,注意力权重为
,即均匀分布。
可能的误区
- 查询的作用:
- 有人可能会认为查询的不同会影响权重,但实际上如果键相同,无论查询如何,相似度都是相同的(因为
对所有 相同)。 - 只有在键不同时,查询的不同才会导致不同的相似度。
- softmax 的性质:
- softmax 对相同的输入值会输出均匀分布。这是 softmax 的一个基本性质。
- 如果输入到 softmax 的所有值相同,输出就是均匀的。
多头注意力(multihead attention)
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖关系)。
因此,允许注意力机制组合查询、键和值的不同子空间表示representation subspaces可能是有益的。
与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的 linear projections)来变换查询、键和值。然后,这
对于
代码实现
在实现过程中通常选择缩放点积注意力,作为每一个注意力头。
py
import math
import torch
from torch import nn
from d2l import torch as d2l
class MultiHeadAttention(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状: (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens的形状: (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
# 先降维拆分:为了多注意力头的并行计算而变换形状
def transpose_qkv(X, num_heads):
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
# 再升维融合:逆转transpose_qkv函数的操作
def transpose_output(X, num_heads):
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
# 实例实用
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
# torch.Size([2, 4, 100])自注意力(self-attention)
定义
将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。
即每个查询都会关注所有键-值对并生成一个注意力输出。由于查询、键和值来自同一组输入,被称为自注意力(self-attention),或内部注意力(intra-attention)。
py
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
# torch.Size([2, 4, 100])计算细节
A:先看向量怎么计算,再看矩阵怎么计算。
第一步:创建各向量 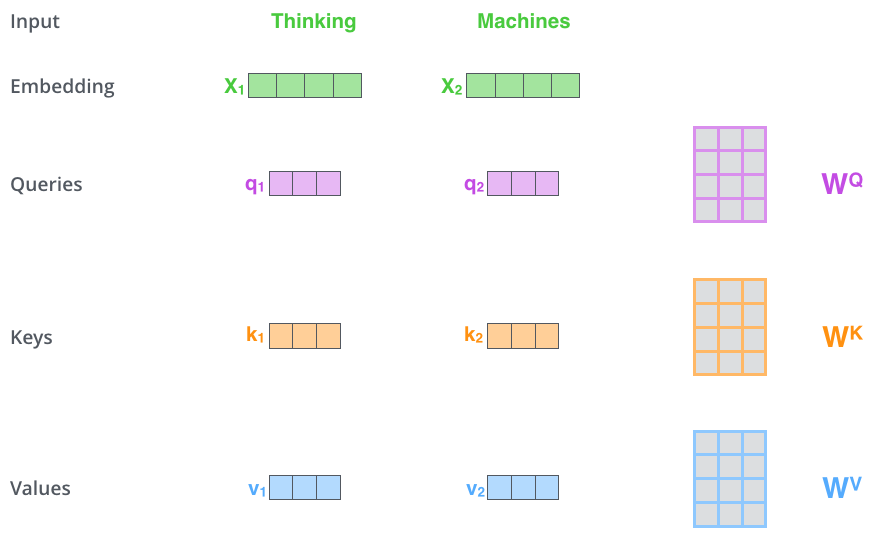 如上,
如上,Thinking词向量
- 乘以
得到 就是 Query向量 - 乘以
得到 就是 Key向量 - 乘以
得到 就是 Value向量
第二步:点积计算注意力分数(Attention Score) 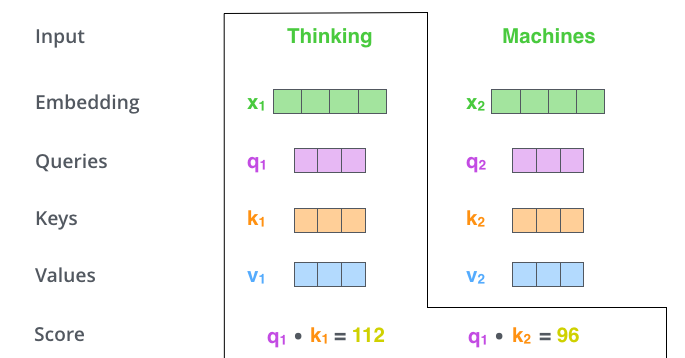 根据
根据Thinking这个词,对句中其他每个词都计算一个分数。这些分数决定在编码Thinking时,需要对句子中其他位置每个词放置多少注意力。
即:通过计算Thinking对应Query向量,和其他位置每个词Key向量点积得到。
第一个位置单词Thinking的Attention Score第一个分数就是
缩放点积注意力(Scaled Dot-Product Attention)公式:
第三步:缩放
把每个分数除以 8(8 是指 Key 向量的长度的平方根,这里 Key 向量的长度是 64)。也可除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定。
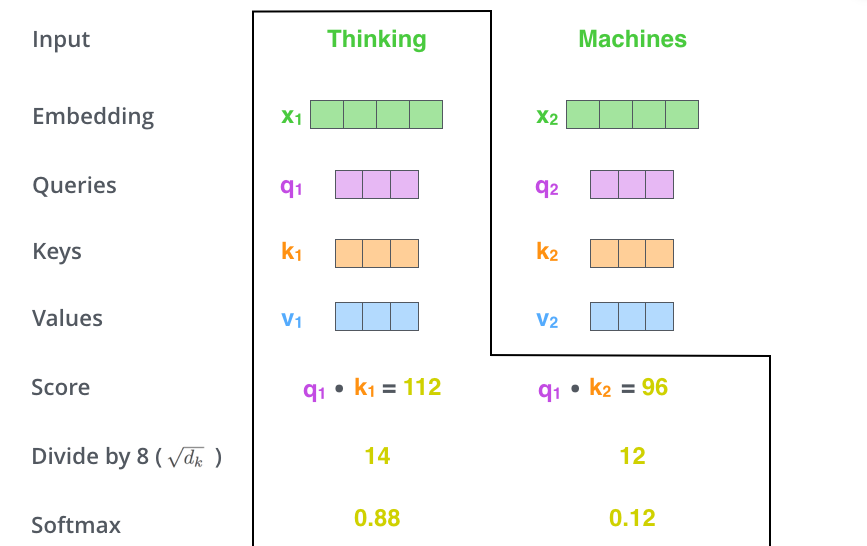
第四步:Softmax 归一化
把这些分数经过一个Softmax层,将分数归一化,这样使得分数都是正数并且加起来等于1。
这些分数决定了在编码当前位置(这里的例子是第一个位置)的词时,对所有位置的词分别有多少的注意力。很明显,当前位置(这里的例子是第一个位置)的词会有最高的分数,但有时,关注到其他位置上相关的词也很有用。
第五步:与Value向量相乘。得到每个位置的分数后,将每个分数分别与每个Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的,这样我们就忽略了这些位置的词。
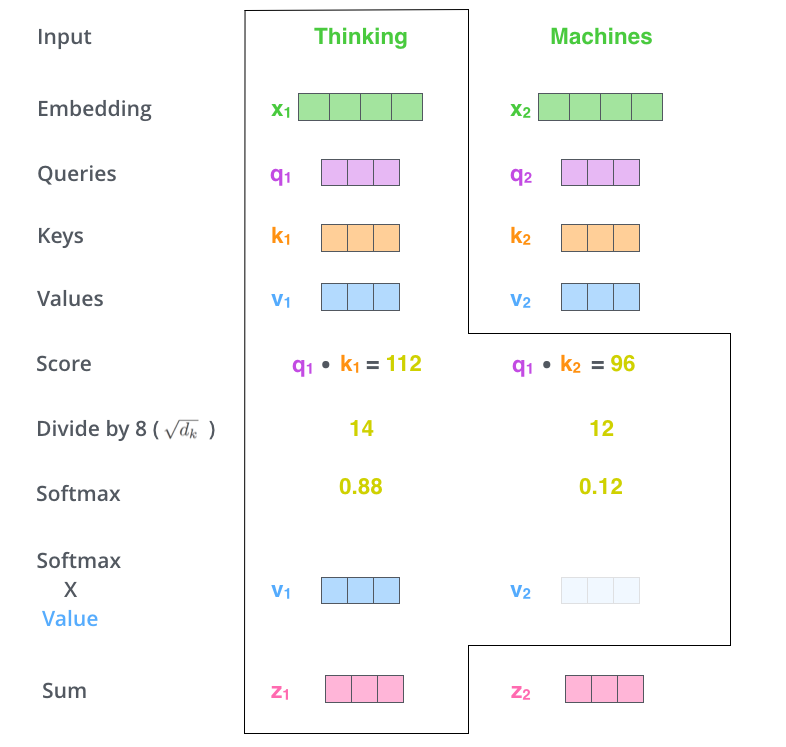
第六步:结果向量相加。把上一步得到的向量相加,就得到了self-attention层在这个位置(这里的例子是第一个位置)的输出。
B:矩阵计算 Self-Attention
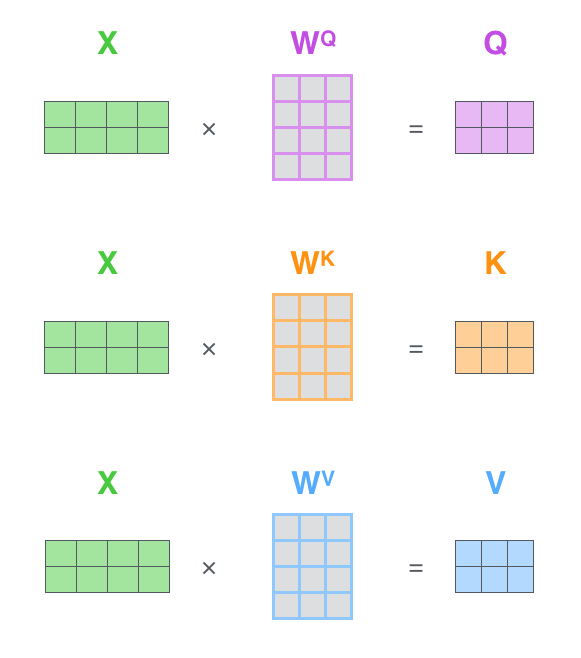 第一步:计算Query, Key, and Value 矩阵,把所有输入向量放到
第一步:计算Query, Key, and Value 矩阵,把所有输入向量放到
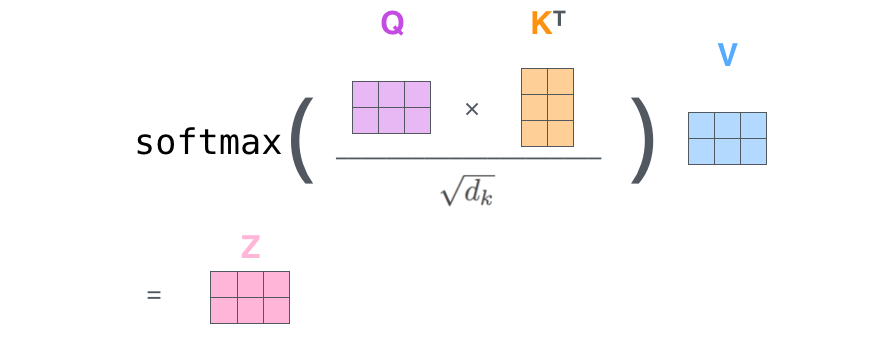 搞定,因为使用矩阵处理,所以把第2步到第6步压缩为一个计算公式,直接得到输出。
搞定,因为使用矩阵处理,所以把第2步到第6步压缩为一个计算公式,直接得到输出。
与 CNN、RNN 比较
 目标:把
目标:把
CNN(卷积神经网络):
- 设卷积核大小
,序列长度 ,输入输出通道数 ,卷积层计算复杂度为 。 - 卷积神经网络是分层的,因有
个顺序操作,最大路径长度为 。
RNN(循环神经网络):
- 更新循环神经网络隐状态时,
权重矩阵和 维隐状态乘法计算复杂度为 ,序列长度为 ,因此计算复杂度为 。 - 有
个顺序操作无法并行化,最大路径长度为 。
自注意力:
- 查询、键和值都是
矩阵,考虑缩放点积注意力, 矩阵乘以 矩阵。之后输出的 矩阵乘以 矩阵,计算复杂度为 。 - 每个词元都通过自注意力直接连接到任何其他词元,有
个顺序操作可以并行计算,最大路径长度也是 。
结论:卷积神经网络和自注意力都拥有并行计算优势,且自注意力最大路径长度最短。但是因为自注意力计算复杂度是关于序列长度的二次方,所以在很长序列中计算会非常慢。
位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。
为了使用序列的顺序信息,通过在输入表示中添加位置编码(positional encoding)来注入绝对或相对位置信息。位置编码可以通过学习得到也可以直接固定得到。
下面介绍固定位置编码:
假设输入
在位置嵌入矩阵
矩阵第
矩阵第
代码实现如下:
py
import math
import torch
from torch import nn
from d2l import torch as d2l
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
# Go!
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)]) 效果如图:可以看到位置嵌入矩阵第 6、7 列和频率高于第 8、9 列。
效果如图:可以看到位置嵌入矩阵第 6、7 列和频率高于第 8、9 列。
点解?在二进制表示中,较高比特位的交替频率低于较低比特位。
py
for i in range(8):
print(f'{i}的二进制是:{i:>03b}')
# 0的二进制是:000
# 1的二进制是:001
# 2的二进制是:010
# 3的二进制是:011
# 4的二进制是:100
# 5的二进制是:101
# 6的二进制是:110
# 7的二进制是:111打印 (0、1、...、7) 的二进制表示形式,可以看到:每 1 个数字、每 2 个数字和每 4 个数字上的比特值在第 1 个最低位、第 2 个最低位和第 3 个最低位上分别交替 0 和 1。